Navigation Structure
Table of contents
Import our datasets:
#import data
dat <- read.table("uk_ipip300_data1.csv", sep = ";", header = TRUE)
Multivariate outliers: Leverage
Use smaller df to evaluate MD of all variables:
extra.labels <- c("Opene_1", "Opene_2", "Opene_3", "Opene_4",
"Agree_1", "Agree_2", "Agree_3", "Agree_4",
"Neuro_1", "Neuro_2", "Neuro_3", "Neuro_4")
dat.extra <- na.omit(dat[,extra.labels])
Mahalanobis distances
Test for outliers (Leverage) using Mahalanobis distances default is a thershold of 1-0.025 Maybe choose more strict threshold of .001:
library(performance)
md <- check_outliers(dat.extra, threshold = stats::qchisq(p = 1 - 0.001, df = ncol(dat.extra)))
print(md)
## Warning: 11 outliers detected (cases 16, 144, 179, 240, 255, 268, 357, 447, 473, 508, 579).
plot(md)
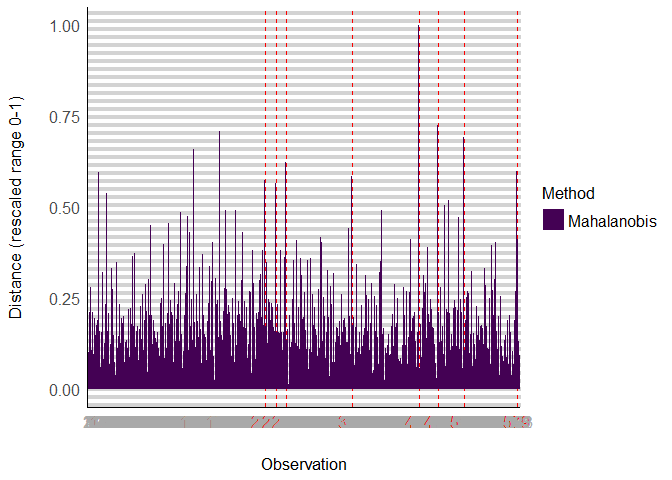
Show outliers:
mdf <- as.data.frame(md)
head(mdf[order(mdf$Distance_Mahalanobis, decreasing=T),],15)
## Distance_Mahalanobis Outlier_Mahalanobis Outlier
## 447 57.89132 1 1
## 473 42.44906 1 1
## 179 41.48188 1 1
## 508 40.46880 1 1
## 144 38.68100 1 1
## 268 36.73672 1 1
## 579 35.28286 1 1
## 16 35.05630 1 1
## 357 34.45752 1 1
## 240 33.90330 1 1
## 255 33.40577 1 1
## 27 31.81040 0 0
## 487 30.71935 0 0
## 482 30.00463 0 0
## 201 29.29412 0 0
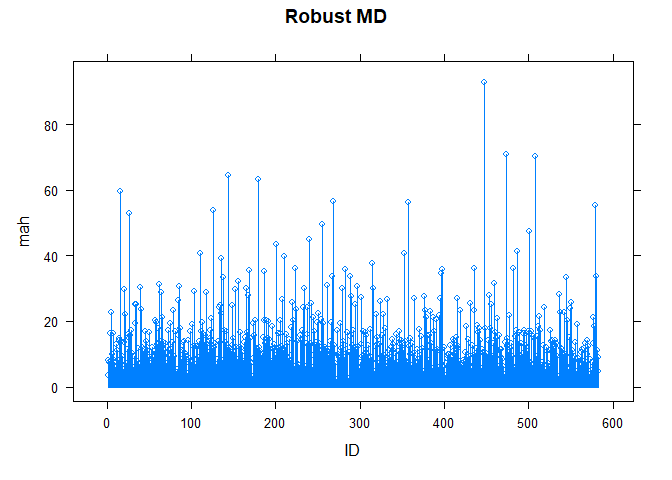
Robost Mahalanobis distances
Alternatively, use robust md (Leverage):
library(faoutlier)
md <- robustMD(dat.extra)
print(md)
## mah p sig
## 447 92.82780 0 ****
## 473 70.84139 0 ****
## 508 70.37589 0 ****
## 144 64.47126 0 ****
## 179 63.23098 0 ****
## 16 59.64405 0 ****
## 268 56.53132 0 ****
## 357 56.20606 0 ****
## 579 55.48568 0 ****
## 126 53.95579 0 ****
plot(md)
Multivariate outliers: Influence
Define a basic lavaan cfa model with 3 facets:
model <- '
op =~ Opene_1 + Opene_2 + Opene_3 + Opene_4
ag =~ Agree_1 + Agree_2 + Agree_3 + Agree_4
ne =~ Neuro_1 + Neuro_2 + Neuro_3 + Neuro_4'
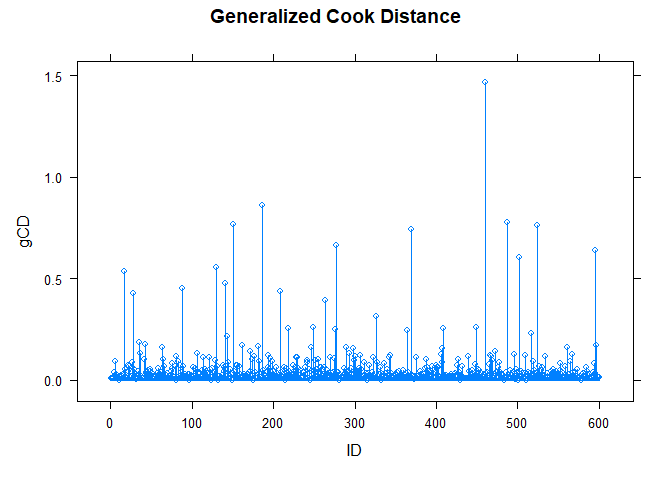
General Cook’s distance
Screen for case influentials using general Cooks distance:
library(faoutlier)
gCDresult2 <- gCD(dat, model, orthogonal=TRUE)
print(gCDresult2)
## gCD
## 460 1.4663159
## 186 0.8598830
## 487 0.7766408
## 150 0.7658846
## 524 0.7618273
## 369 0.7451415
## 277 0.6661814
## 596 0.6387400
## 502 0.6071973
## 130 0.5580723
plot(gCDresult2)
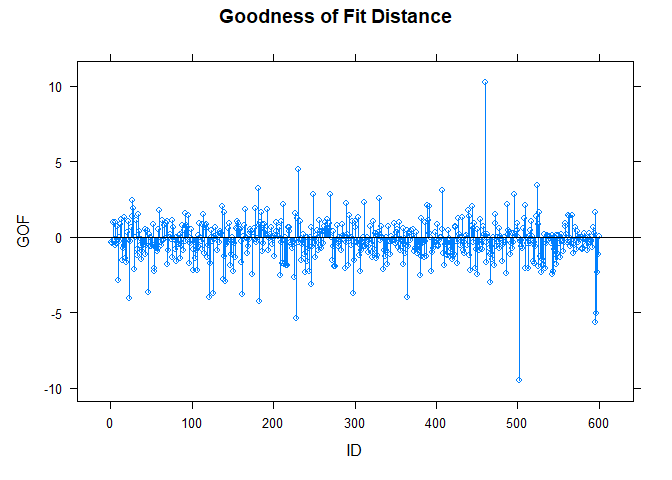
Influence on goodness of fit
go <- GOF(dat, model)
print(go)
## GOF
## 460 10.25004
## 502 -9.46973
## 596 -5.65248
## 228 -5.38852
## 597 -5.02171
## 315 0.00000
## 332 0.00000
## 429 0.00000
## 483 0.00000
## 501 0.00000
## 511 0.00000
## 578 0.00000
plot(go)
Influence on model fit: cfi
Alternatively “rmsea”, “tli…”.
library(influence.SEM)
FI <- fitinfluence("cfi",model,dat)
Graphical exploration of fit influential cases:
explore.influence(FI$Dind$cfi)
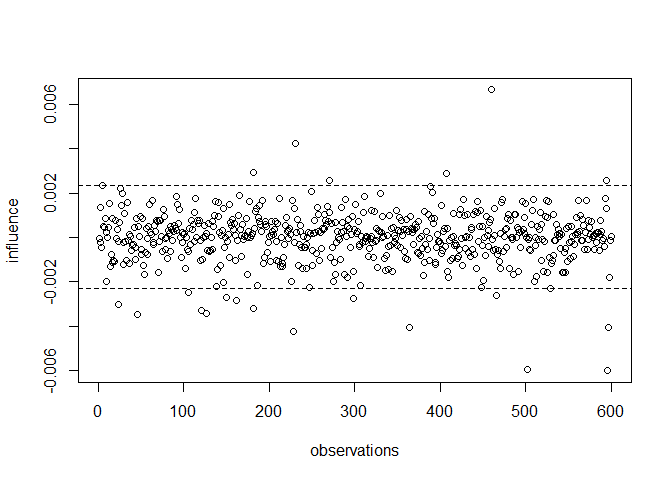
Print highest influential cases on cfi:
head(FI$Dind[order(FI$Dind$cfi, decreasing=F),],10)
## case cfi
## 596 596 -0.006000970
## 502 502 -0.005959073
## 228 228 -0.004250393
## 597 597 -0.004050729
## 364 364 -0.004039169
## 46 46 -0.003472951
## 126 126 -0.003437482
## 121 121 -0.003288414
## 182 182 -0.003179929
## 23 23 -0.003021831
Potentially remove case no. 543 as it has highest neg impact on cfi:
FI.d <- dat[-c(543), ]
# better use subset command
# dat <- subset(dat, id!= 6)
We see cfi has improved:
#New Case influence indicates improved fit regarding cfi
FI.d <- fitinfluence("cfi",model,FI.d)
print(FI.d$Oind)
## cfi
## 0.8579951