Navigation Structure
Table of contents
Prerequisites
I use these libraries:
#import libraries and attach libs
if (!require("pacman")) install.packages("pacman")
pacman::p_load(psych, psychTools, clipr, sjPlot, car, haven)
#alternatively
#library(psych)
#library(psychTools)
#library(clipr)
#library(car)
#library(haven)
Import our datasets:
#import data
dat <- read.table("uk_ipip300_data1.csv", sep = ";", header = TRUE)
dat1 <- read.table("stepd.csv", sep = ";", header = TRUE)
#import xlsx directly
library(readxl)
dat <- read_excel("my_file.xls")
Rename variables
Weird quirk when importing .dat first variable is named “ï..”. Example renames this var:
library(tidyverse)
dat2 <- rename(dat, DyadTime = ï..DyadTime)
Replace in strings
Sometimes people use “,” instead of “.” as decimal sign. We can use the sub function to change this and then change the str to numeric.
dat$dauers <- sub(',', '.', dat$dauers, fixed = TRUE)
dat$dauers <- as.numeric(dat$dauers)
Create long format variables
I regularly need to create some sort of id variables.
#some basic long format stuff
d <- d %>%
group_by(ID) %>%
mutate(time = row_number())
Or count how many cases per group or id.
#how many timepoints on average per participant?
#library(psych)
groupsize <- d %>%
group_by(ID)%>%
count(ID)
If you have one object with baseline scores and want to match it to the long format df
d2 <- left_join(d, t, by = "ID")
Screening
Screen the dataset for Stats, Freq, Graph, Cases, Missing:
library(summarytools)
cor.mat <- select(dat1, iip_acc, iip_cold, iip_dom, iip_sac, iip_int)
dfSummary(cor.mat)
## Data Frame Summary
## cor.mat
## Dimensions: 150 x 5
## Duplicates: 0
##
## ---------------------------------------------------------------------------------------------------------
## No Variable Stats / Values Freqs (% of Valid) Graph Valid Missing
## ---- ----------- ------------------------ -------------------- --------------------- ---------- ---------
## 1 iip_acc Mean (sd) : 13.1 (5.9) 26 distinct values : 150 0
## [integer] min < med < max: . : . (100.0%) (0.0%)
## 1 < 13 < 27 : : :
## IQR (CV) : 8 (0.5) : : : : .
## : : : : : .
##
## 2 iip_cold Mean (sd) : 9.7 (6) 25 distinct values : 150 0
## [integer] min < med < max: . : (100.0%) (0.0%)
## 0 < 9 < 25 . : : : :
## IQR (CV) : 9 (0.6) : : : : . : .
## : : : : : : : : . :
##
## 3 iip_dom Mean (sd) : 5.4 (3.7) 15 distinct values : 150 0
## [integer] min < med < max: : : . (100.0%) (0.0%)
## 0 < 5 < 18 : : : :
## IQR (CV) : 4 (0.7) : : : : .
## : : : : : . . .
##
## 4 iip_sac Mean (sd) : 14.4 (5.9) 26 distinct values : 150 0
## [integer] min < med < max: : : (100.0%) (0.0%)
## 0 < 14 < 31 . : :
## IQR (CV) : 8 (0.4) : : : :
## : : : : :
##
## 5 iip_int Mean (sd) : 6.9 (4.4) 21 distinct values : 150 0
## [integer] min < med < max: : (100.0%) (0.0%)
## 0 < 6 < 24 . : : :
## IQR (CV) : 6 (0.6) : : : : :
## : : : : : : .
## ---------------------------------------------------------------------------------------------------------
Frequency table
By default Freq is ordered by varbiable.
library(summarytools)
freq(dat2$age)
## Frequencies
## dat2$age
## Type: Integer
##
## Freq % Valid % Valid Cum. % Total % Total Cum.
## ----------- ------ --------- -------------- --------- --------------
## 10 1 2.86 2.86 2.86 2.86
## 11 1 2.86 5.71 2.86 5.71
## 12 6 17.14 22.86 17.14 22.86
## 13 8 22.86 45.71 22.86 45.71
## 14 19 54.29 100.00 54.29 100.00
## <NA> 0 0.00 100.00
## Total 35 100.00 100.00 100.00 100.00
Freq ordered by highest frequency first:
freq(dat1$gender, order = "freq")
## Frequencies
## dat1$gender
## Type: Integer
##
## Freq % Valid % Valid Cum. % Total % Total Cum.
## ----------- ------ --------- -------------- --------- --------------
## 1 100 66.67 66.67 66.67 66.67
## 0 50 33.33 100.00 33.33 100.00
## <NA> 0 0.00 100.00
## Total 150 100.00 100.00 100.00 100.00
Omit missings
#copy dataset with no missings
dat.o <- na.omit(dat)
#omit missing per var
#df2 <- df[!is.na(df$x),]
#a more detailed solution.
#filters out missings in x AND y
#can use !if_any for x OR y
df <- df %>%
filter(!if_all(c(x, y), is.na))
Cross-Table
How many have A and B?
library(summarytools)
ctable(dat1$episode,dat1$partner)
## Cross-Tabulation, Row Proportions
## episode * partner
## Data Frame: dat1
##
## --------- --------- ------------ ------------ --------------
## partner 0 1 Total
## episode
## 0 48 (63.2%) 28 (36.8%) 76 (100.0%)
## 1 45 (60.8%) 29 (39.2%) 74 (100.0%)
## Total 93 (62.0%) 57 (38.0%) 150 (100.0%)
## --------- --------- ------------ ------------ --------------
Descriptive statistics
library(psych)
describe(dat1$iip_acc)
## vars n mean sd median trimmed mad min max range skew kurtosis se
## X1 1 150 13.13 5.94 13 13.04 5.93 1 27 26 0.09 -0.63 0.48
Recode variables
Recode items:
1 -> 0
2 -> 1
…
library(car)
dat1$exp_content_r <- car::recode(dat1$exp_content, "1=0; 2=1; 3=2; 4=2")
More logic is available here e.g.: 1 and 2 -> a rest -> b
recode(x, "c(1,2)='A'; else='B'")
Add var label per factor
library(haven)
#Change values from 0 to no exp
dat1$exp_content_r[dat1$exp_content_r =="0"] <- "no exp"
dat1$exp_content_r[dat1$exp_content_r =="1"] <- "med exp"
dat1$exp_content_r[dat1$exp_content_r =="2"] <- "high exp"
#change to factor
dat1$exp_content_r <- as.factor(dat1$exp_content_r)
#result
freq(dat1$exp_content_r)
## Frequencies
## dat1$exp_content_r
## Type: Factor
##
## Freq % Valid % Valid Cum. % Total % Total Cum.
## -------------- ------ --------- -------------- --------- --------------
## high exp 59 39.33 39.33 39.33 39.33
## med exp 34 22.67 62.00 22.67 62.00
## no exp 57 38.00 100.00 38.00 100.00
## <NA> 0 0.00 100.00
## Total 150 100.00 100.00 100.00 100.00
Aggregate variables
Aggregate variables per mean (or: median, sum, min, max):
dat$Extra_total <- apply(dat[,c("Extra_1", "Extra_2", "Extra_3", "Extra_4")], 1, mean, na.rm = TRUE)
Do the same thing with dplyr. This is better imo because you can do multiple vars at once
dat %>%
rowwise() %>%
mutate(Extra_total = mean(c(Extra_1, Extra_2, Extra_3, Extra_4))) %>%
mutate(Neuro_total = mean(c(Neuro_1, Neuro_2, Neuro_3, Neuro_4)))
Calculate classes
We want to divide age in 3 similar sized classes by 33% and 66%:
dat1$age_c <- dat1$age
dat1$age_c[dat1$age_c <= 36] <- 1
dat1$age_c[dat1$age_c > 36 & dat1$age_c <= 47] <- 2
dat1$age_c[dat1$age_c > 47] <- 3
freq(dat1$age_c)
## Frequencies
## dat1$age_c
## Type: Numeric
##
## Freq % Valid % Valid Cum. % Total % Total Cum.
## ----------- ------ --------- -------------- --------- --------------
## 1 50 33.33 33.33 33.33 33.33
## 2 48 32.00 65.33 32.00 65.33
## 3 52 34.67 100.00 34.67 100.00
## <NA> 0 0.00 100.00
## Total 150 100.00 100.00 100.00 100.00
Select cases using subset
Select all cases between age 21 and 28:
dat.t <- subset(dat, age>=21 & age <= 28)
#alternative
dat.t <- filter(dat, age>=21, age <= 28)
Select all cases who are either 18 or 60:
dat.t <- subset(dat, age == 18 | age == 60)
#alternative
filter(mtcars, mpg ==2 1| mpg == 26)
Save dataset
Save R dataframe “dat1” to filename dat2.csv:
write.table(dat1, file="dat2.csv", sep=";", dec = ".")
Save R dataframe “dat1” to filename dat2.sav:
library(haven)
write_sav(dat1, "dat2.sav")
Cronbach’s alpha
Calculate cronbach’s alpha of a defined subset: Alternatively, use CFA See reliabilities.
library(psych)
alpha(select(dat, Extra_1,Extra_2,Extra_3,Extra_4), check.keys =TRUE)
##
## Reliability analysis
## Call: alpha(x = subset(dat, select = c(Extra_1, Extra_2, Extra_3, Extra_4)),
## check.keys = TRUE)
##
## raw_alpha std.alpha G6(smc) average_r S/N ase mean sd median_r
## 0.81 0.81 0.77 0.52 4.4 0.012 3.7 0.89 0.54
##
## lower alpha upper 95% confidence boundaries
## 0.79 0.81 0.84
##
## Reliability if an item is dropped:
## raw_alpha std.alpha G6(smc) average_r S/N alpha se var.r med.r
## Extra_1 0.77 0.77 0.70 0.53 3.4 0.016 0.00497 0.55
## Extra_2 0.77 0.77 0.70 0.53 3.4 0.016 0.00440 0.55
## Extra_3 0.73 0.73 0.65 0.48 2.8 0.019 0.00163 0.46
## Extra_4 0.78 0.78 0.70 0.54 3.6 0.016 0.00021 0.55
##
## Item statistics
## n raw.r std.r r.cor r.drop mean sd
## Extra_1 600 0.79 0.79 0.69 0.62 3.8 1.1
## Extra_2 598 0.79 0.79 0.68 0.61 3.5 1.1
## Extra_3 599 0.84 0.84 0.78 0.70 3.6 1.1
## Extra_4 598 0.78 0.78 0.67 0.60 3.7 1.1
##
## Non missing response frequency for each item
## 0 1 2 3 4 5 miss
## Extra_1 0.00 0.03 0.14 0.16 0.37 0.30 0
## Extra_2 0.01 0.04 0.17 0.19 0.40 0.20 0
## Extra_3 0.01 0.03 0.16 0.17 0.42 0.22 0
## Extra_4 0.01 0.02 0.13 0.14 0.46 0.24 0
Correlation-Table
Call function:
library(devtools)
source_url("https://lucasmaunz.org/download/correlation.R")
Use the definied subset Subset for the table:
cor.mat <- subset(dat1, select =c(iip_acc, iip_cold, iip_dom, iip_sac, iip_int))
Calculate corr table from subset and insert mean and SD: ** p<.01, *p<.05.
c <- correlation_matrix(cor.mat, digits=2, use='lower', replace_diagonal=T, type = "pearson",)
c <- data.frame(SD = format(round(sapply(cor.mat, sd, na.rm = TRUE),2),nsmall=2), c)
c <- data.frame(M = format(round(colMeans(cor.mat),2),nsmall=2), c)
print(c)
## M SD iip_acc iip_cold iip_dom iip_sac iip_int
## iip_acc 13.13 5.94
## iip_cold 9.73 6.02 0.25**
## iip_dom 5.42 3.67 0.12 0.45**
## iip_sac 14.41 5.92 0.73** 0.23** 0.21*
## iip_int 6.86 4.43 0.34** 0.14 0.48** 0.41**
Copy corr-table to clipboard to paste into Excel
library(clipr)
write_clip(c)
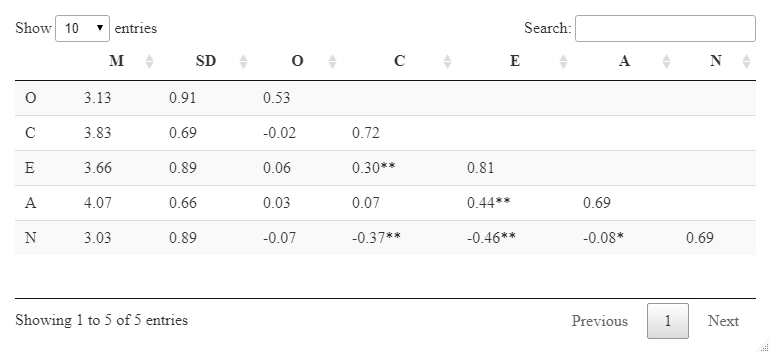
Correlation-Table with Cronbach’s alpha
Create a correlation table with Cronbach’s alpha on the diagonal
# library(devtools)
# source_url("https://lucasmaunz.org/download/correlation.R")
# library(psych)
# library(dplyr)
# Correlation table with alpha coef on diagonal
# create subset of vars for cor table
cor.mat <- select(dat1, O,C,E,A,N)
# create simple cor table
c <- correlation_matrix(cor.mat, digits=2, use='lower', replace_diagonal=T, type = "pearson",)
# add alpha values on diagonal
# order sensitive! o -> c -> e -> a -> n
diag(c) <- c(
round(psych::alpha(select(dat1,c("O1","O2","O3","O4","O5")),check.keys=TRUE)$total$std.alpha, 2),
round(psych::alpha(select(dat1,c("C1","C2","C3","C4","C5")),check.keys=TRUE)$total$std.alpha, 2),
round(psych::alpha(select(dat1,c("E1","E2","E3","E4","E5")),check.keys=TRUE)$total$std.alpha, 2),
round(psych::alpha(select(dat1,c("A1","A2","A3","A4","A5")),check.keys=TRUE)$total$std.alpha, 2),
round(psych::alpha(select(dat1,c("N1","N2","N3","N4","N5")),check.keys=TRUE)$total$std.alpha, 2)
)
#insert SD and M
c <- data.frame(SD = format(round(sapply(cor.mat, sd, na.rm = TRUE),2),nsmall=2), c)
c <- data.frame(M = format(round(colMeans(cor.mat),2),nsmall=2), c)
#copy to clipboard
#library(clipr)
write_clip(c)
You get something linke this
library(DT)
datatable(c)